Introduction
Whenever fetching data from a backend server, you may be naive enough to think that the response is always predictable, and your data's shape will always be the same. The only problem is that, even though you may think the data is of a certain shape, a backend server can be updated at any time in the future without the front end knowing.
Problem
Let's produce an example to demonstrate the problem and how we can future-proof our front-end API calls to handle any unexpected changes.
Let's say we want to fetch a User from the backend that looks like this:
So, our frontend might be tempted to type the response like so:
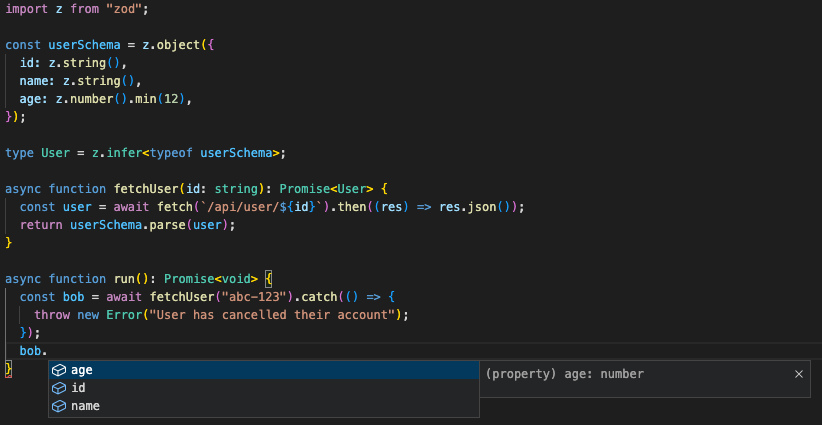
Calling this function will give us a nice auto-complete on the user's properties:

The problem with this approach is that we are putting trust the backend will always return the same properties, so we tell TypeScript we expect a User to be returned every time.
What happens in the future when this user deletes their account and the company's policy is to delete their name and age from the database for privacy reasons? We may receive this instead from the backend:
If we run a user through this calculateDateOfBirth function, we will run into runtime issues, even though during development time, TypeScript did not pick up any issues.
This unfortunately will return NaN and could affect the operation of our application.
Solution
Now, we can check all the properties that exist at runtime, but that would be tedious for larger objects and nested properties. I recommend a runtime validation library such as yup, joi or zod. For this example, I will be using zod, which has the best TypeScript inference support for a better developer experience. Let's refactor our fetch function.
As you can see, we use zod to define a schema. The schema is then used to parse our backend data (that we don't trust). We also define a type that is inferred from the schema. This means that we don't need to double-handle schemas and types and they won't be out of sync.
If the parsing fails, we can catch the error and process it higher up. The error thrown will give us details about what attributes failed validation and we can act accordingly.
The bonus of using the .parse() function from zod is that it will automatically return a fully typed object based on the schema. Unlike the initial example, we don't have to manually annotate the typings as it is automatically inferred.