
Last week at work, we implemented a caching mechanism for Chargebee API calls to avoid API restrictions with Chargebee. This meant we could memorise the result of an API call in our persistent store. This yielded two advantages:
- We could avoid throttling from Chargebee, and as a result, affect our users’ experience. If the input of the API call yields the same output multiple times, we can consider these as calls that perhaps shouldn't contribute to our API throttling limit.
- We could serve up the data back to our users faster, due to the round-trip to our persistent store being quicker than making the API call to Chargebee.
Implementation
This made me curious about what an implementation would look like in native JavaScript. Turns out it can be quite simple. My naive approach was to first serialise the expensive function and its dependencies (arguments). This is a similar concept to React's useMemo hook. From there, use the serialised string as its unique identifier (or key). Every time the same combination of the function and its arguments is encountered again, we check the cache for the same key and return the result from the cache.
This is what this may look like:
Test function
Now we need to create an expensive function that takes time to complete to test on our runMemo function.
To run the expensive function against the cache, we create 3 runs:
- Run A: Initial call when the cache is empty. This should force the expensive function to run in its entirety.
- Run B: The same function and same arguments from Run A. This should trigger a cache hit, and return the result from the cache, rather than running the expensive function again.
- Run C: The same function, with different arguments. This should trigger a cache miss, which means we have to run the expensive function again.
Results
These were the results from my local machine:
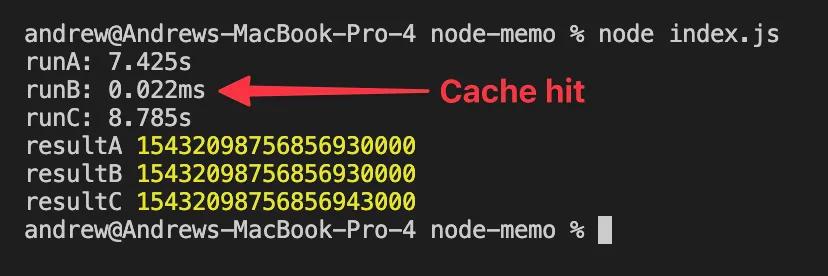
As we can see, the cache behaved as we expected and we saved a good 7 seconds on Run B. This is of course a very basic implementation of a cache. Building upon this, we could make the following improvements:
- Store metadata relating to the cache to determine how current the data is. This can help in determining the validity of the data.
- Evict stale data periodically to ensure the data is up to date.
- Create an interface to interact with the cache manually.
- Allow a mechanism for the consumer to forcefully bypass the cache and run the expensive function.
The full runnable code can be found here: